Moneo
Top-Tier Software & Product Development Company - We’re your next tech partner, delivering innovative projects, AI solutions, and digital transformation for your business.
Our Blogs
MySQL’de Tarihleri Yaşa Çevirme Yöntemleri
MySQL’de tarihleri yaşa çevirmek için kullanabileceğiniz farklı yöntemler vardır. Bu yazıda, MySQL’de tarihleri gün ve ay değerlerini de dikkate alarak yaşa çevirmenin çeşitli yollarını inceleyeceğiz.Yaş bilgisi, her gün değişen bir veri olduğu için tarih bazlı bir kolon, yaşın her an doğru ve güncel bir şekilde hesaplanmasını sağlayarak daha esnek bir çözüm sunar.🔹 TIMESTAMPDIFFİnceleyeceğimiz yöntemler arasında, tarih farkını hassas bir şekilde hesaplamakta ve genellikle kullanım kolaylığı ve doğruluk açısından tercih edebileceğiniz en iyi yöntemdir.SELECT TIMESTAMPDIFF(YEAR, birthday, NOW()) AS ageFROM customers;Bu sorguda TIMESTAMPDIFF fonksiyonu, iki tarih arasındaki farkı belirli bir birimde hesaplamamıza olanak tanır. İlk parametre de farkı hangi birimde hesaplayacağımızı belirtiyoruz (burada yıl). İkinci parametre de hangi kolon için hesap yapacağımızı ve son olarak da hangi tarihten çıkaracağımızı belirterek aradaki yıl farkını bulmuş oluyoruz bu sayede kişinin yaşını elde ediyoruz.🔹DATEDIFFBu yöntemde, elde edilen gün sayısını 365'e bölmek bazı durumlarda yanıltıcı olabilir çünkü her yıl 365 gün değildir.Bu nedenle, bu basit bölme işlemiyle elde edilen yaş bilgisi, gerçek yaş ile tam olarak uyuşmayabilir. Bu durumu göz önünde bulundurarak, bu yöntemi kullanırken dikkatli olunmalıdır.SELECT FLOOR(DATEDIFF(NOW(), birthday)/365) AS ageFROM customers;DATEDIFF fonksiyonu, iki tarih arasındaki gün farkını sağlar. Elde edilen gün farkı daha sonra 365'e bölünerek yıla çevrilir. FLOOR fonksiyonu kullanılarak ondalık kısmı atılır ve kişinin yaş bilgisi elde edilmiş olur.🔹 TO_DAYSBu yöntemde de bir önceki örnekteki gibi 365'e bölmek bazı durumlarda yanıltıcı olabilir.SELECT FLOOR((TO_DAYS(NOW()) - TO_DAYS(birthday)) / 365) AS ageFROM customers;TO_DAYSfonksiyonu kullanarak yapılan bu yöntemde, birthdayve şu anki tarih yani NOW()arasındaki gün farkı hesaplanır. Ardından bu fark, 365'e bölünerek yaşa çevrilir.🔹 DATE_FORMAT ve FROM_DAYSBu karmaşık yöntemde, yaş bilgisini elde etmek için kullanılabilir ama diğer yöntemlere göre daha fazla adım içermektedir. Önceki yöntemde kullanılan 365'e bölme işleminden farklı olarak, bu yöntem daha doğru bir sonuç sağlayabilir,SELECT DATE_FORMAT(FROM_DAYS(DATEDIFF(now(), birthday)), '%Y')+0 AS ageFROM customers;Bu sorguda DATEDIFF ile bulunan gün farkı, FROM_DAYS ile bir güne çevrilir ve ardından DATE_FORMAT fonksiyonu ile yıl formatına dönüştürülür. Sonuç olarak kişinin yaş bilgisi elde edilir.Örneğin bugünün tarihini 13 mart olarak düşünürsek tüm bu yöntemlerin çıktısı şu şekilde gözükecektir.Bu yazıda, MySQL’de tarihleri ay ve gün değerlerini de dikkate alarak yaşa çevirmek için kullanılabilecek çeşitli yöntemleri inceledik. Hangi yöntemin sizin durumunuza daha uygun olduğunu belirlemek için her birini kendi tablonuz üzerinden test edebilirsiniz. Bu yöntemler dışında kullandığınız yöntemleri yorumlarda belirtebilirsiniz. 🐬MySQL’de Tarihleri Yaşa Çevirme Yöntemleri was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Laravel Polymorphic Relations: Custom Morph Map
Selamlar👋 Bugün Laravel Eloquent ORM kullanırken polimorfik ilişkilerde yaşayabileceğiniz uç noktadaki bir problemi inceleyeceğiz.Öncelikle basit bir örnek ile polimorfik ilişki nedir bunu açıklayalım.Makale ve video paylaşılan bir platformda, hem makalelerin hem de videoların etiketlenmesini sağlamak için polimorfik yapı kullanırız.Post, Video ve Tag modelleri ile taggables isminde bir ara tablo kullanarak bu ilişkiyi kurarız.posts id - integer name - string videos id - integer name - string tags id - integer name - string taggables tag_id - integer taggable_id - integer taggable_type - stringtaggables tablosundaki veri Laravel standartlarında aşağıdaki gibi olacaktır.taggablesPeki biz Laravel standartlarında olmayan bir poliformik tabloyu Laravel projemizde kullanmak istersek ne yapmamız gerekir? Yapısal olarak birebir aynı ama _type kolonunda farklı keyler kullandığımız bir senaryoda veriyi güncellemeden Eloquent ORM’de nasıl işleyebiliriz? Makale ve videolar için bir de kategori ilişki olduğunu ve bu tablonun standartlara uymadığını varsayalım.categoryablesHem Category hem Tag için Post modelinde Laravel’in standart polimorfik tanımlamasını yapıp Post’un hem Tag hem Category ilişkilerine ulaşmaya çalıştığımızda kategorilere ulaşmamız mümkün olmayacak.$post = Post::find(1);dd($post->categories, $post->tags);Bu durumda Laravel bize çözüm olarak AppServiceProvider içerisinde morphMap güncellemesi yapmamızı tavsiye ediyor.public function boot(): void{ Relation::morphMap([ 'video' => Video::class, 'post' => Post::class, ]);}Tekrar kontrol ettiğimizde bu seferde her şeyin standartlara uyduğu Tag ilişkisini kaybettiğimizi görüyoruz.Şimdi çözmemiz gereken çok önemli bir noktadayız. Öncelikle standartları bozmamak için AppServiceProvider üzerinde morphMap yapmaktan kaçınıyoruz. Sonrasında standartlara uymayan Category polimorfik ilişkisi için Post modeli üzerinde bir güncelleme yapıyoruz. Bu güncelleme Post-Category arasındaki ilişkiyi sağlarken varolan ilişkileri bozmadan kullanmamızı sağlayacak.// App/Models/Post.phppublic function morphToMany( string $related, string $name, ?string $table = null, ?string $foreignPivotKey = null, ?string $relatedPivotKey = null, ?string $parentKey = null, ?string $relatedKey = null, ?string $relation = null, bool $inverse = false): MorphToMany { Relation::morphMap($this->customMorphMap($related)); $args = func_get_args(); return parent::morphToMany(...$args);}private function customMorphMap(string $related): array{ return match ($related) { Category::class => [ 'post' => Post::class ], default => [ Post::class => Post::class, ], };}Burda çözdüğümüz problem tam olarak şu Laravel poliformik ilişkilerde sadece tek bir type anahtarı kullanmamıza izin veriyor. Biz ise birden fazla ilişki için birden fazla type kullanıyoruz.Yukarıdaki değişiklik sayesinde birden fazla ilişkili tabloyu doğru şekilde kullanabildik.Bunu yapmanın bir diğer yolu ise moneo/laravel-morphmap paketini kullanmak. Bu paketi kurduktan sonra yapmamız gereken bir iki ufak ekleme var. Aşağıda eklenen kısımları görebilirsiniz.<?phpnamespace App\Models;use Illuminate\Database\Eloquent\Model;use Illuminate\Database\Eloquent\Relations\MorphToMany;+use Moneo\LaravelMorphMap\Database\Eloquent\Concerns\HasCustomMorphMap;class Post extends Model{+ use HasCustomMorphMap; public function __construct(array $attributes = []) {+ $this->customMorphMap = [+ Category::class => 'post',+ ]; parent::__construct($attributes); } public function tags(): MorphToMany { return $this->morphToMany(Tag::class, 'taggable'); } public function categories(): MorphToMany { return $this->morphToMany(Category::class, 'categoryable'); }}Bu sayede çok daha basit bir şekilde ilişki bazında polimorfik key’lerinizi yönetebilirsiniz.Yeni bir yazıda görüşmek üzere✋moneo/laravel-morphmapLaravel Polymorphic Relations: Custom Morph Map was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Easy Serialization in Doctrine
Doctrine ORM kullandığımız projelerde entity sınıflarından türetilen objeleri kolayca JSON’a çeviremiyoruz. Çoğunlukla entity sınıflarında property’ler private olarak tanımlandığı için json_encode fonksiyonu obje içerisindeki verilere erişemiyor.Örnek olarak aşığıdaki User entity sınıfı göz önünde bulundurulabilir. Bu sınıftan türetilen bir obje json_encode ile işlenemez.#[Table(name: 'users'), Entity(repositoryClass: UsersRepository::class)]final class User{ #[Id, Column(type: 'integer')] private int $id; #[Column(type: 'string')] private string $name; #[Column(type: 'string')] private string $email; #[Column(type: 'string')] private string $password; private string $tempAvatar = '/tmp/no-photo.jpg';}Peki bir objeyi json’a çevirmek istersen ne ile karşılacağız? Bunun cevabını net görebilmek için objenin çıktısına bakalım.public function debug(EntityManagerInterface $entityManager): void{ $userRepository = $entityManager->getRepository(User::class); $user = $userRepository->findOneBy(['email' => '[email protected]']); dd($user, json_encode($user));}Çıktı olarak User objesinin detaylarını görebiliyorken boş bir json string görüyorum.Çözüm Olarak Ne Yapabiliriz?Çözüm olarak Doctrine Entity sınıflarımıza JsonSerializable özelliği katacağız.Öncelikle tek tek tüm entitiy sınıflarında bunu eklemeye uğraşmak yerine bir abstract entity sınıfı oluşturmamız gerekiyor.abstract class Entity implements \JsonSerializable{ protected array $hidden = []; public function jsonSerialize(): array { $this->hidden[] = 'hidden'; $reflection = new \ReflectionClass($this); $properties = array_filter($reflection->getProperties(), function (\ReflectionProperty $property) { if (!$property->getAttributes(Column::class)) { return false; } if (in_array($property->getName(), $this->hidden)) { return false; } return true; }); $objectVars = []; foreach ($properties as $property) { $objectVars[$property->getName()] = $property->getValue($this); } return $objectVars; }}Burada yaptığımız işlem bir obje json’a çevirilmek istendiğine hangi verinin json’a çevirileceğini belirliyor. ReflectionClass ile objenin tüm property değerlerine ulaşabiliyoruz. Buna ek olarak Laravel Eloquent’te olduğu gibi bir hidden kullanımı da ekledik. Ayrıca property’leri filtrelediğimiz kısımda eğer bu property bir Column değil ise json’a eklememesini de sağlamış olduk. Bu kısmı ihtiyacımıza göre değiştirebilir ve geliştirebiliriz.User entity sınıfını abstract Entity sınıfından kalıtımla almak ve password değerini gizlemek için User sınıfını aşağıdaki gibi düzenliyorum.#[Table(name: 'users'), Entity(repositoryClass: UsersRepository::class)]final class User extends Entity{ protected array $hidden = ['password']; #[Id, Column(type: 'integer')] private int $id; #[Column(type: 'string')] private string $name; #[Column(type: 'string')] private string $email; #[Column(type: 'string')] private string $password; private string $tempAvatar = '/tmp/no-photo.jpg';}Bu şekilde kullandığımda ise çıktı aşağıdaki gibi oluyor ve istediğim datayı json’da kullanabiliyorum.Ayrıca Symfony projelerinizde Serializer kullanarak da bu işlemi yapabilirsiniz.public function __invoke(SerializerInterface $serializer){ $user = new User( name: 'Mücahit Cücen', email: '[email protected]' ); $json = $serializer->serialize($user, 'json'); dd($user, $json);}Bu paketi Symfony Framework olmadan da kullanabilirsiniz.Özet olarak objelerimizdeki private property değerlerini json’a çevirirken kullanmak istiyorsan sınıflarımıza JsonSerializable interface’ini ekleyebiliriz.Başka bir yazıda görüşmek üzere 👋Easy Serialization in Doctrine was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Laravel Eloquent: Tarih Kolonlarında whereBetween Kullanımının Riskleri
Laravel Eloquent’te whereBetween kullanımı genellikle yaygın bir yöntemdir, ancak tarih içeren kolonlarda bu yöntemin dikkatli bir şekilde kullanılması gerekmektedir. Bu yazıda, whereBetween’ın bu durumda potansiyel risklerini inceleyip, daha güvenli alternatiflere odaklanacağız.Nedir ve Nasıl Kullanılır?whereBetween, belirli bir aralıktaki verileri sorgulamak için kullanılan bir Eloquent sorgu yöntemidir.Bir users tablomuz olduğunu düşünelim. 18 ve 45 yaş aralığındaki kişileri getirmek için whereBetween ile örnek bir sorgu yazalım.$users= User::query() ->whereBetween('age', [18, 45]) ->get();Sorgu sonucunda 18 ve 45 dahil olmak üzere bu iki değer arasında kalan tüm kişilere erişmiş oluyoruz. Kullanması gayet basit olan bu yöntem ile yazdığımız sorguyu da kısaltmış oluyoruz.Kullanımının RiskleriPerformans olarak daha hızlı olan bu yöntem tarih içeren kolonlarda yanlış sonuç getirmenize sebep olabiliyor. Peki nasıl?Sizden users tablosuna son bir hafta içerisinde gelen kullanıcıları listelemenizi istediklerini düşünelim. Bunun için bir command oluşturalım ve whereBetween ile sorgumuzu yazalım.$today = Carbon::now();$lastWeek = $today->subWeek();$users = User::query() ->whereBetween('created_at', [$lastWeek, $today]) ->get();$this->info('Bir hafta içerisinde gelen kullanıcı sayısı: '. $users->count());Carbon kütüphanesini kullanarak bugünün ve bir hafta öncesinin tarihini değişkene atadık, sonrasında whereBetween içerisine bu değişkenleri ekleyerek sorgumuzu tamamladık. Commandı çalıştıralım ve kaç adet kullanıcı geldiğini görelim.Bir hafta içerisinde 46.805 adet kullanıcı geldiğini görüyoruz. Aynı sorguyu bir de whereDate yöntemi ile yazalım.$today = Carbon::now();$lastWeek = $today->subWeek();$users = User::query() ->whereDate('created_at', '>=', $lastWeek) ->whereDate('created_at', '<=', $today) ->get();$this->info('Bir hafta içerisinde gelen kullanıcı sayısı: '. $users->count());Sorgumuzu whereDateile düzenledik. Commandımızı tekrar çalıştıralım ve sonucu görelim.Bu sonuçta ise 58.347 adet kullanıcı getirildi. Peki aradaki 10 bin fazla kayıt neden getirildi? Hangisi doğru? Bunu anlamak için iki sorgununda SQL çıktılarına bakalım.Elequent’in toRawSql methodunu kullanarak iki sorgununda SQL’lerini görebiliriz.#whereDateselect * from `users` wheredate(`created_at`) >= '2024-01-28'and date(`created_at`) <= '2024-02-04'#-------------------------------------------##whereBetweenselect * from `users` where `created_at`between '2024-01-28 13:40:29' and '2024-02-04 13:40:29'SQL’leri incelediğimizdewhereBetween ile yazmış olduğumuz sorguda saatinde dahil edildiğini, whereDate kullanımında ise dahil edilmediğini görüyoruz. Yani biz whereBetween kullandığımızda o gün içerisinde mesela 13.30 da gelen bir kullanıcıyı listelemedik ve eksik kayıt getirmiş olduk.Sonuç olarak, tarih bazlı sorgularda, Eloquent’in whereDate veya whereTime gibi yöntemlerini kullanmak, whereBetween kullanımının oluşabilecek sorunlarına karşı daha güvenilir ve kesin çözümler sunar. Bu sayede tarih sorgularınızda eksiksiz ve doğru sonuçlara ulaşabilirsiniz.Laravel Eloquent: Tarih Kolonlarında whereBetween Kullanımının Riskleri was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Laravel Migration Nedir?
Laravel MigrationSelamlar, bu yazımda sizlere Laravel de migration yapısını, basit ve örnekli şekilde anlatacağım.Laravel Migration Nedir?Laravel Migration, Laravel de kod aracalığıyla veritabanınızda bir tablo oluşturmanıza ve bu tablolarınızı düzenlemenize olanak sağlayan yapıdır.Laravel geliştiricilerin veritabanı değişikliklerini yönetmelerine yardımcı olan bir özelliktir. SQL ifadelerini manuel olarak yazmaya gerek kalmadan sütun, tablo veya dizin ekleme veya kaldırma gibi veritabanı değişikliklerini işlemek için kullanılan yöntemdir.Laravel Migration Nasıl Kullanılır ?Migration dosyaları 2 adet fonksiyondan oluşmaktadır. Bu fonksiyonların ilki “up” fonksiyonudur. Bu fonksiyon migration dosyası tetiklendiğinde çalışıp içinde Schema classının yönlendirmesiyle verilen oluşturma ya da güncelleme işlemlerini gerçekleştiren fonksiyondur. Diğer fonksiyonumuz ise “down” fonksiyonudur. Bu fonksiyon ise çalıştırdığımız migrationu geri almak istediğimizde çalışacak fonksiyondur. Bir örnek vermek gerekirse bir tabloya sütun ekledik fakat yanlış bir güncellemeye sebep olduk. Bunun için down fonksiyonu içinde tam tersi işlemleri yapıp çalıştırabiliriz. Fakat prod database’lerde bu işlemler sakıncalı olacağı için bu durumları nasıl yönetmemiz gerektiğini makalenin ilerleyen kısımlarında anlatacağım.Şimdi kısaca migration dosyalarının içeriğinden bahsedeyim. Öncelikle migration dosyaları nasıl oluşturulur ?Adım 1: Migration Oluşturmaphp artisan make:migration create_teams_tableBu komut, database/migrations klasörüne aşağıdaki migration dosyasını ekler. Aşağıdaki ekran görüntüsünde olduğu gibi id ve timestamps sütunları default olarak dosya oluşturulurken gelmektedir.Peki oluşturduğumuz bu dosyayı nasıl düzenleyeceğiz ?Adım 2: Migration Dosyasını DüzenlemeOluşturulan migration dosyasını düzenleyerek, veritabanında yapmak istediğiniz değişiklikleri tanımlayabilirsiniz.Örnek olarak yukarıda oluşturduğumuz teams tablosuna bazı sütunları ekleyelim.Burada tablo yeni oluşacağı için Schema classının create fonksiyonu kullanıyoruz. Yukarıda olduğu gibi sütunumuzun hangi değerde veriler barındıracağını belirtip daha sonra ismini belirtiyoruz. İlişkisel sütunlar kullanmak istediğimizde foreignId şeklinde belirterek ve sonuna constrained ekleyerek migration çalışırken otomatik olarak bu sütunun coachs tablosunda ki id ye bakacağını belirtmiş oluyoruz. Aynı şekilde nullable olmasını istediğimiz sütunlarıda nullable()fonksiyonuyla belirtebiliyoruz.Düzenlediğimiz dosyayı nasıl çalıştırabiliriz ?Adım 3: Migration’ı ÇalıştırmaMigration dosyalarımızı çalıştırmadan önce php artisan migrate:status komutuyla kontrol edebiliriz. Bu komutu çalıştırdığımda aşağıda ki gibi bir çıktı ile karşılaşacağız. Burada daha önce çalıştırdığımız migration dosyalarımız ve bekleyen migration dosyalarımızı görmekteyiz.Daha sonrasında ise bekleyen migrationlarımızı çalıştırmak için aşağıdaki komutu kullanabiliriz.php artisan migrateBu komut, tüm bekleyen migration’ları sırayla çalıştırır ve veritabanınızı günceller. Eğer bu komutu sonuna :fresh ekleyerek çalıştırırsanız tüm veritabanınızı sıfırdan migrate etmenizi sağlar.Laravel Migration Kullanırken Dikkat Edilmesi Gereken Noktalar Nelerdir ?Eski migration dosyalarını güncellemek: Migration dosyaları bir kere çalışmak üzerine tasarlanmıştır. Çalışan bir migration dosyası tekrardan düzenlenmemeli. Bunun yerine düzenlemek veya eklenmek istenen alan yeni bir migration dosyası açılarak Schema classının table fonksiyonu ile mevcut tablo belirtilip gerekli işlemler yapılmalıdır.Down Metodu: Her migration dosyasında bir down metodu olmalıdır. Bu metod, bir migration geri alındığında yapılacak işlemleri tanımlar. Fakat production database’lerde geri alma işlemi uygulanmaz. Bunun yerine yeni bir migration açarak düzenlemek istediğimiz tabloyu burada düzenleyerek tekrardan çalıştırarak migration yapısını ileri yönde kullanmamız gerekir.İsimlendirme: İsimlendirmeler, bir migration dosyasının ne yaptığını açık bir şekilde belli etmelidir. Çünkü migration yapısında çok fazla dosyayla çalışma ihtimaliniz yüksek olacağından bu belirti dosyalar arasında rahat ayrıştırma sağlayacaktır. Örneğin mevcut bir games tablomuz olsun. Ve biz bu tabloya bir adet referee kolonu eklemek isteyelim. Oluşturacağımız dosyanın adı yukarıda bahsettiğimiz gibi yapılan işlemi açıkça belirtmelidir. Yani dosya ismimiz add_referee_column_on_games_table olmalıdır.Tips and tricksModel yaratırken “-m” komutuyla otomatik olarak migrationıda yaratabilirsiniz.php artisan make:model Game -m2. Tablo/Sütun varlığını şu şekilde kontrol edebilirsiniz:if (Schema::hasTable('games')) { // games tablosu mevcut mu kontrolü yapar}if (Schema::hasColumn('games', 'rank')) { // games tablosunda rank kolonu var mı kontrolü yapar.}3. Tablo güncellerken grup olarak eklemek istediğiniz kolonları aşağıdaki gibi ekleyebilirsiniz:Schema::table('games', function (Blueprint $table) { $table->after('rank', function ($table) { $table->string('last_match_score'); $table->string('last_match_team_id'); $table->string('last_match_city_id'); });});Laravel Migration Nedir? was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
4 minutes read

Laravel OpenSpout — Fast Excel Export
Laravel OpenSpout — Fast Excel ExportBu yazıda Laravel projelerinizde excel export/import ihtiyacınız olduğunda kullanabileceğiniz OpenSpout paketini inceleyeceğiz. Fakat yazıda import üzerinde durmayacağım, daha çok export üzerinden ilerleyeceğim.Toplulukta OpenSpout paketinin alternatifleri de var, fakat hepsi her ihtiyaca cevap veremeyebiliyor. Ayrıca yazıda neden bu paketi tercih etmeliyiz? Avantajları/Dezavantajları nelerdir? bunları konuşacağız.Neden OpenSpout?OpenSpout paketini üst düzey durumlara cevap bir paket olarak görebiliriz. Küçük verilerlerle çalışırken Laravel-Excel paketi gayet güzel bir seçenektir. Fakat olay küçük verilerden çıkıp 100.000–1.000.000 satır verileri rapora yazmaya geldiğinde imdat çığlıklarınıza OpenSpout paketi yetişecektir.Soruyu hem örnekler üzerinden, hem de avantajları/dezavantajları üzerinden detaylandıralım.AvantajlarYüksek yazma/okuma hızına sahiptir. Milyonlarca veriyi dakikalar içerisinde rapora yazabilir.Dosya boyutu oldukça düşüktür. Laravel-Excel paketiyle kıyaslayınca “MB” yerine “KB” konuşmaya başlıyor.ref: https://github.com/openspout/openspout/blob/4.x/docs/faq.md#how-long-does-it-take-to-generate-a-file-with-x-rowsDezavantajlarÇizelgeler ve formülleri desteklemez.Paket oldukça basit tutulmuş. O yüzden kod üzerinde okunabirlik ve kullanım pratikliği Laravel-Excel paketine göre daha düşüktür. Laravel-Excel paketi, kendi içerisinde birçok şeyi kendi hallederken, OpenSpout ile arkada halledilen işleri sizin halletmeniz gerekiyor. Laravel’e başladıktan 3 yıl sonra ilk kez Pure PHP yazdığınızı varsayın :)Openspout KullanımıPaketin avantajlarından bahsedersen görseldeki tabloda XLSX formatı için 6 milyon hücreye yazma hızı 8-10 dakika olarak belirtilmiş. Gerçekten ne kadar sürüyor, küçük bir gerçek hayat örneği üzerinden denemek istedim. Laravel'de Faker ile 3 milyon dummy kullanıcı datası oluşturdum.Tüm veriyi çekip OpenSpout paketi ile excel raporuna yazdım. 3 milyon datayı tek seferde yazamayacağım için chunk ile 1000'er şekilde yazdırdım.TestExcelExportRuntimeCommandhttps://medium.com/media/55f31f80eebebf7fadf0369917de9d10/hrefOutput3 milyon veriyi excel raporuna yazma süresiMySQL veritabanında users tablosundan 3 milyon kaydı (4 sütun: id, name, email, email_verified_at) tek seferde 54 saniyede çekiyor. Paketin FAQ kısmında 6 milyon hücreye yazma hızı 8–10 dakika olarak belirtilmişti.3 milyon satır x satır başı 4 hücre = 12 milyon hücre12 milyon hücreye yazma işlemini 140 saniye (2–3 dakika) içerisinde tamamladı. Verileri çekme süresini dahil etsek bile oldukça kısa sürede yazıyor.NOT: Tabi her hücre içerisinde yazılan verilerin içeriği değiştikçe/büyüdükçe yazma süresi de doğru orantıda değişecektir. Buradaki amacımız aşağı yukarı gerçek hayat örnekleri üzerinden testlerimizi gerçekleştirmekti.Dosya Boyutu3 milyon satır, toplam 6 milyon hücresi dolu olan excel dosyasının boyutu ise diğer paketlerin oluşturduğu boyuta göre oldukça düşük, sadece 131.5 MB!SonuçOpenSpout hız açısından çok iyi performans çıkarıyor. Özellikle büyük veri seti olduğunda kısa sürede yazma/okuma işlemlerini bitirmekle öne çıkıyor. Hatta OpenSpout, dosya boyutu ne kadar büyük olursa olsun 3 MB’den daha az memory kullanmayı vadediyor.Kullanım kolaylığı açısından ise Laravel-Excel öne çıkıyor. OOP’den daha fazla yararlanmak ve hızlı iş çıkarmak istendiğinde Laravel-Excel tercih edilebilir.Laravel-Excel aslında PhpSpreadsheet paketini bağımlılık olarak kullanıyor. PhpSpreadsheet paketinin mimarisi, hücrelere direkt olarak memory üzerinden erişmek üzerine kurulu olduğu için memory kullanımında darboğaz yapabiliyor. Bunun için çeşitli çözümler üretilse de mimarisinden dolayı performansa iyi yönde etki edecek herhangi bir çözüm yok. Örneğin caching yapmak da yine network trafiği oluşturacağı için performansa kötü anlamda etki ediyor.Laravel OpenSpout — Fast Excel Export was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Laravel Relation Kullanımı ve N+1 Problemi
PHP ile bir proje geliştirirken veritabanımızda çok sayıda alan oluşturuyoruz ve bu alanları birbirine bağlamamız gerekebiliyor. Laravel Eloquent ORM’nin sağladığı relationship özelliğini kullanmak geliştiricinin hayatını kolaylaştırıyor ve büyük veritabanlarında çalışırken harcanan eforu azaltıyor. Buna rağmen Laravel’de relationship kullanırken de bilmemiz gereken bazı detaylar bulunuyor.Öncelikle relationshipin ne olduğunu ve hangi amaçla kullanıldığını anlayalım.Yukarıdaki örnekte bir takımlar tablomuz ve bir maçlar tablomuz bulunuyor. Maçlar tablomuzda ev sahibi takım ve deplasman takımı şeklinde iki tane alanımız var. İlgili takımların detaylarını maçlar tablomuza yazarsak tablo çok şişecektir. Bu nedenle takımlarla ilgili bilgileri takımlar tablomuzda tutuyoruz ve bunları ID’leri üzerinden maçlar tablomuza bağlıyoruz. İşte relationship basitçe bu oluyor.Peki Laravel’de bunun pratiği nedir? Hemen inceleylim.Öncelikle migration kullanarak tablolarımızı oluşturmamız gerekiyor:Schema::create('teams', function (Blueprint $table) { $table->id(); $table->string('name'); $table->timestamps();});Schema::create('games', function (Blueprint $table) { $table->id(); $table->foreignId('home_team_id')->constrained('teams'); $table->foreignId('away_team_id')->constrained('teams'); $table->timestamps();});Diyagramdaki yapıyı Laravel Migration ile kurmak istersek bu şekilde kolaylıkla relationship oluşturabiliyoruz. Foreign ID tanımlamasını yaptıktan sonra constrained metodunu çağırarak bağlayacağımız tablonun ismini veriyoruz.Şimdi ise modellerimizde gerekli tanımlamaları yapalım:class Game extends Model{ public function homeTeam() { return $this->belongsTo(Team::class, 'home_team_id'); } public function awayTeam() { return $this->belongsTo(Team::class, 'away_team_id'); }}Bir maç kaydımızda sadece tek bir ev sahibi/deplasman takımı olabilir. Bu nedenle Game modelimizde belongsTo kullanarak Team modelimize takımı bağladık. belongsTo metodunun ilk parametresine bağlayacağımız modelin sınıfını veriyoruz, eğer foreign key’imiz model isminden farklı ise (örneğin model ismi Team, foreign key ismi home_team_id) ikinci parametre olarak foreign key’imizi verebiliyoruz.class Team extends Model{ public function homeGames() { return $this->hasMany(Game::class, 'home_team_id'); } public function awayGames() { return $this->hasMany(Game::class, 'away_team_id'); }}Bir takım kendi stadında veya deplasmanda birden fazla maç oynamış olabilir. Bu nedenle hasMany kullanarak tanımlamalarımızı yapıyoruz.Bu örnekte en sık kullanılan relation tanımlama türü olan One To Many kullandım. Bunun dışında ihtiyacınıza göre One To One, One ToMany, Many To Many türünde tanımlamaları da kullanabilirsiniz.Oluşturduğumuz relation’ı kullanmak istediğimizde de Controller üzerinden Blade dosyamıza ilgili Game modelini yolluyoruz. Blade üzerinde {{ $game->homeTeam->name }} şeklinde çağırıp o maçın ev sahibi takımının ismini yazdırabiliyoruz.Çok kolay değil mi? Aslında değil. Laravel projelerinde relation yapısı mevcutsa muhtemelen en büyük hatalar relation’ı kullanırken yaşanıyor.N+1 Problemi923 statements were executed, 915 of which were duplicated, 8 unique.Yukarıdaki kullanım muhtemelen ilk bakışta gözünüze doğru göründü. Fakat bu kullanımın ardından muhtemelen arka planda onlarca mükerrer sorgu atılacak. İşte bu problemin adı N+1.Kısaca özetleyecek olursak, bir sayfamızda maçlarımızı gösterdiğimizi var sayalım. Bu maçları döngü içinde gösterip relation’ımızı çağırdığımızda her seferinde yeni bir sorgu oluşacak. Bunu önlemek için ise Laravel’in sağlamış olduğu Eager Loading yöntemini kullanıyoruz.Öncelikle nasıl yapmamamız gerektiğini öğrenelim:Game::all() şeklinde veri tabanımızda bulunan tüm maçları çağırıp ön tarafta foreach kullanarak bunları bastırıyoruz, döngünün içinde de relation kullanarak ev sahibi ve deplasman takımlarının isimlerini çekiyoruz. Bu şekilde kullanmak göstereceğim gibi bir sorgu silsilesine neden oluyor.Laravel Debugbar (barryvdh/laravel-debugbar)Game::with(['homeTeam', 'awayTeam'])->get();Eğer maçları bu şekilde çağırmış olsaydık tüm takımlar tek bir sorguda maç modelimizin içine girecek, hem çalışma hızı büyük ölçüde artacak hem de mükerrer sorguların önüne geçmiş olacağız.Sonrası ise bu şekilde.Nested Relation kullanımlarında N+1 problemiTakım modelimizin içinde oyuncular ilişkimizin olduğunu ve maçlarımızı gösterirken kadroyu göstermemiz gerektiğini de var sayalım. Sonucunda aşağıdaki gibi bir sorgumuz olacaktır:Game::query() ->with([ 'homeTeam', 'awayTeam',])->get();Bu durumda takım ilişkimizin içindeki oyuncu ilişkisi de N+1 problemi ile karşılaşacaktır. Bu durumda takımlarımızın içine oyuncularımızı da yüklememiz gerekiyor.Game::query() ->with([ 'homeTeam', 'awayTeam', 'homeTeam.players', 'awayTeam.players',])->get()Bu şekilde bir N+1 problemini daha aşmış olduk. Tüm bunların sonucunda sadece 5 sorgu çalıştırılıyor. Eğer eager loading kullanmamış olsaydık 29 sorgu çalıştırılacaktı ve bunların 28'i mükerrer olacaktı.API Resource içinde Eager LoadingLaravel ile yapılan API projelerinde daha anlamlı response’lar dönmek için Resource sınıflarını kullanıyoruz. Resource sınıflarını kullanırken de relationlarımızın sadece yüklendiğinde response üzerinde dönülmesi için de bir metod bulunuyor.public function toArray(Request $request): array{ return [ 'name' => $this->name, 'players' => PlayerResource::collection($this->whenLoaded('players')), ];}Örneğin takım listeleme servisimizde bu şekilde bir API Resource ile yanıt dönüyoruz. Oyuncu bilgilerini almak istediğimizde de whenLoaded kullanarak ilgili relation’ı çağırıyoruz ve bu relation sadece eager loading yapılmışsa çağrılıyor.N+1 problemini önlemek için alternatif yollarModelinizdeki relation’ı sorgularınızı düzenlemeden sürekli çağırmak istiyorsanız model üzerinde istediğiniz relationları yazarak ilgili modele attığınız sorgularda with kullanımı yapmadan N+1 problemlerini önleyebilirsiniz.protected $with = ['homeTeam', 'awayTeam', 'homeTeam.players', 'awayTeam.players'];Direkt olarak game modelimde with ile ihtiyacım olan relationları çağırarak sorgularımda ek bir düzenleme yapmadan problemi önlemiş oldum.Proje içinde bulunan sorgulardaki N+1'leri tespit etmekEğer problemin çıkış noktasını anladıysanız sadece sorgularınızı okuyarak bile oluşan N+1 problemlerini görebilirsiniz. Fakat development yaparken proje üzerindeki lazy load edilen relationları devre dışı bırakıp hangi modellerde N+1 problemi gerçekleştiğini görebilirsiniz.public function boot(): void{ // app/Providers/AppServiceProvider.php Model::preventLazyLoading(!app()->isProduction());}Eğer AppServiceProvider içinde bu tanımlamayı yaparsanız development ortamlarınızda N+1 problemi olduğunda hangi modelde sorun olduğunu da belirten aşağıdaki exception fırlatılacaktır.Illuminate\Database\LazyLoadingViolationExceptionAttempted to lazy load [homeTeam] on model [App\Models\Game] but lazy loading is disabled.Ek olarak Laravel Query Detector paketini geliştirme ortamlarınıza kurarak eğer sayfalarınızda N+1 problemi olan modeller varsa bunların bir alert ile gösterilmesini sağlayabilirsiniz.Makalenin sonucunda Laravel’de basit olarak Relationship kullanımını ve en çok karşılaşılan sorunlardan biri olan N+1 problemini Laravel’de nasıl önleyeceğimizi öğrenmiş olduk. Yazdığım ipuçlarından yola çıkarak kendi projelerinizde de doğru relation kullanımları ile daha sağlıklı geliştirmeler yapabilirsiniz.Laravel Relation Kullanımı ve N+1 Problemi was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
6 minutes read

Spatie Browsershot İle Laravel’de PDF Oluşturmak
Spatie Browsershot, Laravel uygulamalarında web sayfalarını tarayıcı üzerinden görüntülemek ve PDF formatında çıktı almak için kullanılan bir araçtır. Puppeteer node.js kütüphanesini temel alarak, kullanımı kolay ve hızlı bir şekilde web sayfalarının ekran görüntülerini veya PDF dosyalarını oluşturmamıza olanak tanır.Nasıl Kullanılır?Spatie Browsershot ile kolayca PDF oluşturmak için aşağıdaki gibi bir kullanımı uygulayabiliriz.Browsershot::url('https://example.com') ->save('example.pdf');Yukarıdaki belirtilen URL’deki web sayfasının example.pdf adında bir PDF dosyası oluşturuyoruz. Ek olarak uzantısını example.jpg olarak değiştirerek ekran görüntüsünü jpg olarak alabiliriz.Boyutlandırma ve FormatlamaPDF çıktısını özelleştirmek için Spatie Browsershot’in sağladığı bazı özellikleri kullanabiliriz. Örneğin, sayfa boyutu, sayfa formatı, margin değerleri gibi parametreleri belirleyerek çıktıyı kişiselleştirebiliriz.Browsershot::url('https://example.com') ->waitUntilNetworkIdle() // Ağ trafiğinin durmasını bekler ->format('A3') ->paperSize($width, $height) ->margins($top, $right, $bottom, $left) ->savePdf($path.'/example.pdf');Aşağıda, PDF çıktısının görüntüsü bulunmaktadır:Html veya Blade Kullanarak Pdf OluşturmaSpatie Browsershot, sadece URL değil, aynı zamanda doğrudan HTML veya Blade şablonları kullanarak da PDF oluşturabiliriz.$html = "<div> <h1 style='display: flex;justify-content:center'>Laravel Spatie Browsershot ile Pdf Oluşturma</h1> <p style='font-size:x-large;'>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.</p> </div>";Browsershot::html($html) ->margins(5, 25, 0, 25) ->savePdf($path.'/example.pdf');Çıktı:Blade şablonları kullanarak sayfalarımızı daha fazla özelleştirmek istersek, PDF’imizde her sayfada gözükecek header ve footer ekleyebiliriz.$html = view('pdf.example')->render(); // İçerik$header = view('pdf.header')->render(); // Logo$footer = view('pdf.footer')->render(); // Sayfa BilgisiBrowsershot::html($html) ->showBrowserHeaderAndFooter() ->headerHtml($header) ->footerHtml($footer) ->savePdf($path.'/example.pdf');Çıktı:Özet olarak Spatie Browsershot, web sayfalarını görüntülemenin yanı sıra, çeşitli özelleştirme seçenekleri sunarak Laravel uygulamalarında PDF oluşturmayı kolaylaştırır. Bu sayede kullanıcılar sayfa boyutu, sayfa formatı, margin değerleri, header ve footer ekleyerek istedikleri çıktıyı elde edebilirler.Spatie Browsershot İle Laravel’de PDF Oluşturmak was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
10 months ago
3 minutes read

Debezium ile Veritabanınızdaki Değişiklikleri Yakalayın
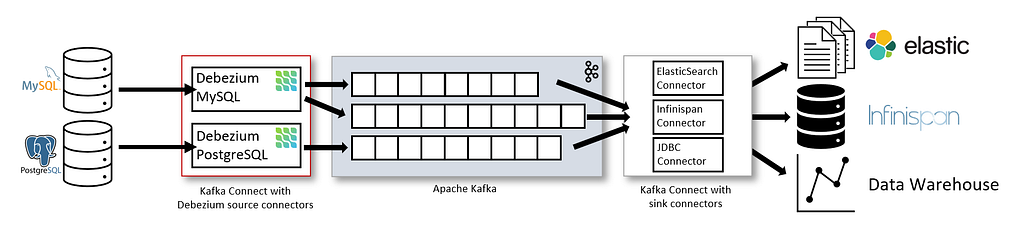
Yazılım geliştirme dünyasında veritabanları bizim için vazgeçilmez bir araçtır. Onlar sayesinde verilerimizi kayıt altında tutar, ihtiyaç duyduğumuzda kullanırız. Bu yazımda size veritabanlarında yapılan değişiklikleri real-time olarak nasıl dinleyebileceğimizi, kafka üzerinden bu eventleri nasıl yakalayabileceğimizi ve development ortamımızı docker üzerinden nasıl kurabileceğimizi anlatacağım.Debezium Nedir?Debezium, Java ile geliştirilmiş, veritabanı üzerindeki değişiklikleri dinleyen, bunları belirli kafka topiclerine gönderen bir Change Data Capture (CDC) aracıdır. Debezium sayesinde veritabanındaki değişiklikleri anlık olarak dinleyebilir, bu verileri başka bir uygulama üzerinden kullanabilirsiniz. Debeziumun burada bize sağladığı en önemli özelliklerden birisi gönderilen veri değişikliklerinin sırasının korunması ve her bir eventin sadece bir kere gönderilmesidir. Böylece güvenilebilir mimariler inşa edilmeye olanak sağlanmış oluyor.Debeziumu kullanabilmenin 3 farklı yolu var: kafka connect, debezium server ve debezium engine.Debezium’a Ne Zaman İhtiyaç Duyarız?Debeziuma ihtiyaç duyacağımız birden fazla durum vardır. Bunlar, veri replikasyonu, servisler arası veri paylaşımı, ETL besleme vs. olabilir. Benim durumumda bir DB’ye yazma işlemi yapan 2 uygulama arasında veri değişikliklerini gerçek zamanlı yakalayarak iki uygulama arasında senkronizasyonu kolaylaştırdı. Debezium sayesinde legacy appten DB ye yazılan verileri güncel app içerisine aktarabildim böylece legacy appi maintain etme yükümlülüğümü azaltıp bir bağımlılığı daha koparmış oldum.Debezium ServerDebezium server, kafkadan bağımsız bir şekilde çalışıyor. Bunun için döküman üzerinde belirtildiği gibi bir sunucunun içerisine kurulum yapmanız gerekiyor. Kafka Connect kullanmak istemeyenler için geliştirilmiş bir çözüm.Debezium EngineDebezium engine ise var olan java uygulamalarınızın içerisinde embedded olarak çalıştırmak için kullanılan versiyonu. Eğer bir java uygulamanız için CDC ihtiyacınız var ise kafka ekosistemini projenize dahil etmek istemiyorsanız debezium engine kullanabilirsiniz.Kafka ConnectDebeziumun bir diğer kurulumu ve bizim de bu yazımızda değineceğimiz kısmı ise kafka connect’tir. Öncelikle kafka connect’in ne olduğuna değinelim.Kafka connect, kafka ekosistemine diğer veri sistemlerinden stream oluşturmaya yaran bir framework’tür. Bu sayede kafkaya canlı veri stream edebiliyoruz ya da kafkadan başka bir veri sistemine veri gönderebiliyoruz.https://debezium.io/documentation/reference/3.2/architecture.htmlYukarıdaki görsel üzerinden mimariyi inceleyelim. Kafka connect üzerinden debezium CDC kurulumu yaptınız. Burada çalışan debezium, MySQL’in binlog dosyasını dinlemeye alıyor. MySQL veritabanında yapılan işlemleri log dosyası üzerinden yakalıyor, dosyanın en son neresini okuduğunu not alıyor ki uygulamanın çökmesi durumunda kaldığı yerden devam edebilsin. Sonrasında config üzerinden tanımladığınız kural setine göre eğer bir event göndermesi gerekiyor ise bu eventi kafka topiclerine gönderiyor. Daha sonrasında da gelen topiclere isterseniz consume edin, isterseniz bir sink connectörü kullanıp başka bir yere yönlendirin. Örneğin elastic sink üzerinden elesticsearch indexlerinizi üretebilirsiniz ya da mongo sink üzerinden mongodb’ye verinizi replika edebilirsiniz.Ben bu yazımda kafka client üzerinden topiclere nasıl subscribe olabileceğimizi anlatacağım.Kurulumdan Önce…Geliştirme ortamımızı docker üzerinden oluşturacağız. Debezium’un resmi dökümanları üzerindeki tutorial yazısında docker üzerinden kurulum gösteriliyor ama ben aşağıdaki sebeplerden ötürü oradaki kurulum adımlarınızı takip etmenizi önermiyorum:1 - Resmi tutorial içerisindeki image’lar Apple Silicon işlemciler ile uyumlu değil.2- Tutorial içerisindeki gösterilen container’lerin hepsi debezium tarafından yayımlanmış, bunlara kafka ve zookeeper dahil. Community desteği ve apple silicon sorunlarından dolayı debezium/kafka image’ını kullanmak mantıklı değil.3- Tutorialde gösterilen kafka kurulumunda zookeeper kullanılıyor. Kafka’nın 3.3 versiyonundan sonra kafkayı kraft modunda zookeeper bağımlılığı olmadan kullanabiliyoruz. Bu sayede bir container’ı daha sistemden çıkarabiliriz demek.4- Tutorialde docker compose yok, uygulamayı docker-compose üzerinden çalıştırma yükümlülüğü de kullanıcıya bırakılmış.KurulumKurulumda kafka image’ı için bitnami tarafından yayınlanmış bitnami/kafka kullanacağız. Community desteği ve dökümantasyon içeriği bakımından bu image’ı tercih ettim.services: kafka: image: bitnami/kafka:3.8 ports: - "9094:9094" environment: - KAFKA_CFG_NODE_ID=0 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER volumes: - kafka-data:/bitnami/kafka healthcheck: test: ["CMD-SHELL", "kafka-topics.sh --bootstrap-server localhost:9092 --list || exit 1"] interval: 10s timeout: 5s retries: 5 start_period: 30svolumes: kafka-data:Burada değinmek istediğim bir kaç nokta var. Kafkaya burada hem controller hem de broker rolü veriyoruz. Sonrasında daKAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093Bu config ile kafkayı kraft modunda başlatıyoruz. Böylece zookeeper için bir container ayağa kaldırmamız gerekmiyor. Ayrıca 9094 portundan da local makine üzerinden kafkaya bağlanabiliyoruz. Consumer appimizi henüz dockerise etmediysek network problemi yaşamamak için dışarıdan bağlanabiliyoruz.Kafka UIŞimdi sırada opsiyonel bir adım var. Development ortamında kafkayı debuglamak için provectuslabs/kafka-ui kullanmanızı öneririm.services: kafka: image: bitnami/kafka:3.8 ports: - "9094:9094" environment: - KAFKA_CFG_NODE_ID=0 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER volumes: - kafka-data:/bitnami/kafka healthcheck: test: ["CMD-SHELL", "kafka-topics.sh --bootstrap-server localhost:9092 --list || exit 1"] interval: 10s timeout: 5s retries: 5 start_period: 30s kafka-ui: image: provectuslabs/kafka-ui:latest ports: - "8080:8080" environment: - KAFKA_CLUSTERS_0_NAME=local - KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092 - KAFKA_CLUSTERS_0_METRICS_PORT=9092 - KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME=connect - KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS=http://connect:8083 depends_on: kafka: condition: service_healthy connect: condition: service_healthy restart: unless-stoppedvolumes: kafka-data:Böylece kafka connect bağlantı durumunu, topiclerdeki mesajları, offsetleri ve daha bir çok şeyi http://localhost:8080/dashboard adresinden görüntüleyebilirsiniz.Kafka ConnectDebezimun aslında bir kafka connect ürünü olduğunu söylemiştim. Bu sebeple önce kafka connect kurmamız gerekiyor, sonrasında da bunun içerisine debeziumu yüklememiz gerekiyor.Kafka connect image’ı için bir kaç alternatif var, ben burada confluentinc/cp-kafka-connect kullanmayı tercih ettim. Bunun nedeni, zengin dökümantasyon desteği, confluent hub üzerinden diğer kafka connect ürünlerine erişim, RestAPI ile connector yönetimi, debezium desteği ve kolay kurulum adımları.Önce bir Dockerfile dosyası oluşturalım..├── docker│ └── kafka-connect│ └── Dockerfile└── docker-compose.ymlVe sonrasında da base image’ımızı alıp içerisine debezium yükleyelim.FROM confluentinc/cp-kafka-connect:7.9.2RUN confluent-hub install --no-prompt debezium/debezium-connector-mysql:3.1.2confluent-hub cli toolu üzerinden connectörleri rahatlıkla yükleyebiliyoruz.Sonrasında docker-compose stackimiz içerisine ekleyelim.services: kafka: image: bitnami/kafka:3.8 ports: - "9094:9094" environment: - KAFKA_CFG_NODE_ID=0 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER volumes: - kafka-data:/bitnami/kafka healthcheck: test: ["CMD-SHELL", "kafka-topics.sh --bootstrap-server localhost:9092 --list || exit 1"] interval: 10s timeout: 5s retries: 5 start_period: 30s kafka-ui: image: provectuslabs/kafka-ui:latest ports: - "8080:8080" environment: - KAFKA_CLUSTERS_0_NAME=local - KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092 - KAFKA_CLUSTERS_0_METRICS_PORT=9092 - KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME=connect - KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS=http://connect:8083 depends_on: kafka: condition: service_healthy connect: condition: service_healthy restart: unless-stopped connect: build: context: . dockerfile: docker/kafka-connect/Dockerfile ports: - "8083:8083" environment: - CONNECT_BOOTSTRAP_SERVERS=kafka:9092 - CONNECT_GROUP_ID=connect-cluster - CONNECT_CONFIG_STORAGE_TOPIC=my_connect_configs - CONNECT_OFFSET_STORAGE_TOPIC=my_connect_offsets - CONNECT_STATUS_STORAGE_TOPIC=my_connect_statuses - CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR=1 - CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR=1 - CONNECT_STATUS_STORAGE_REPLICATION_FACTOR=1 - CONNECT_KEY_CONVERTER=org.apache.kafka.connect.json.JsonConverter - CONNECT_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter - CONNECT_REST_PORT=8083 - CONNECT_REST_ADVERTISED_HOST_NAME=connect - CONNECT_PRODUCER_MAX_REQUEST_SIZE=15728640 - CONNECT_MAX_REQUEST_SIZE=15728640 depends_on: kafka: condition: service_healthy restart: unless-stopped healthcheck: test: "curl -f http://localhost:8083/ || exit 1" interval: 10s timeout: 5s retries: 3 start_period: 30svolumes: kafka-data:Şu haliyle debezium için gerekli minimum stackimiz hazır hale geldi. Kafka (Kraft mode), kafka connect ve debezium. Şimdi kafka connect üzerinden bir debezium task’i oluşturup MySQL veritabanındaki değişiklikleri dinleyebiliriz.MySQL HazırlıkMySQL veritabanının debezium tarafından dinlenebilmesi için yapmamız gereken bazı ayarlar var. Bunlar user oluşturma, permission, binlog dosyası vs. olarak gitmekte. İşlemler için buradaki debezium dökümanını inceleyebilirsiniz.Debezium Taski OluşturmaÖnce docker compose up -d komutu ile stackimizi ayağa kaldıralım. Sonrasında, kafka connect içerisinde RestAPI üzerinden debezium taski oluşturacağız. Buradaki task oluşturma stratejisi tamamen size kalmış. İsterseniz statik bir json dosyası üzerinden curl isteği yapabilirsiniz, isterseniz bir app üzerinden dinamik bir şekilde task oluşturabilirsiniz. Ben json üzerinden curl isteğiyle size göstereceğim.Önce register-mysql.json adında bir dosya oluşturalım..├── docker│ └── kafka-connect│ └── Dockerfile├── register-mysql.json└── docker-compose.ymlSonrasında dosya içeriğini oluşturalım:{ "name": "mysql-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.hostname": "host.docker.internal", "database.port": "3306", "database.user": "root", "database.password": "", "database.server.id": "184055", "topic.prefix": "my_topic_prefix", "database.include.list": "awesomeappDB", "table.include.list": "awesomeappDB.products,awesomeappDB.orders", "schema.history.internal.kafka.bootstrap.servers": "kafka:9092", "schema.history.internal.kafka.topic": "schema-changes.awesomeappDB", "tombstones.on.delete": "false", "snapshot.mode": "schema_only", "max.batch.size": "2048", "max.queue.size": "8192" }}Mevcut config ayarlarına debezium MySQL dökümanı üzerinden ulaşabilirsiniz.Buradaki config ile beraber aslında bir debezium taski oluşturuyoruz. Debeziumun hangi veritabanını dinleyeceğini, hangi tabloları dinleyeceğini vs. configi buradan ayarlıyoruz. Daha sonrasındacurl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @register-mysql.jsoncurl üzerinden isteğimizi yapıp debezium taskimizi başlatıyoruz.İşlemlerimiz bu kadar. Artık consumer appimizden kafkaya bağlanıp topiclere subscribe olabiliriz. Debezium her tablo için bir topic oluşturuyor. Örneğin, bizim config setimize göre awesomeappDB veritabanında products ve orders tablolarındaki transactionlar debezium tarafından kafkaya gönderilecek. Her topic için de my_topic_prefix şeklinde bir prefix eklenecek. Yani ürünler tablosu için consume etmemiz gereken topic “my_topic_prefix.awesomeappDB.products” olacaktır.ÖzetBu yazımda size en basit haliyle development ortamında debezium stackini nasıl oluşturabileceğimizi anlattım. Aslına bakarsak debezium ve kafka connect tarafında henüz bahsetmediğim onlarca özellik ve ayar var. Bunları ihtiyaçlarınıza göre ayarlayıp kullanabilirsiniz, resmi dökümanlar ve google bu özelliklerin kullanımı konusunda yardımcı olacaktır.Umarım faydalı olmuştur, bir sonraki makalede görüşmek üzereDebezium ile Veritabanınızdaki Değişiklikleri Yakalayın was originally published in Moneo on Medium, where people are continuing the conversation by highlighting and responding to this story.
8 months ago
10 minutes read
Our Posts
Our Events
